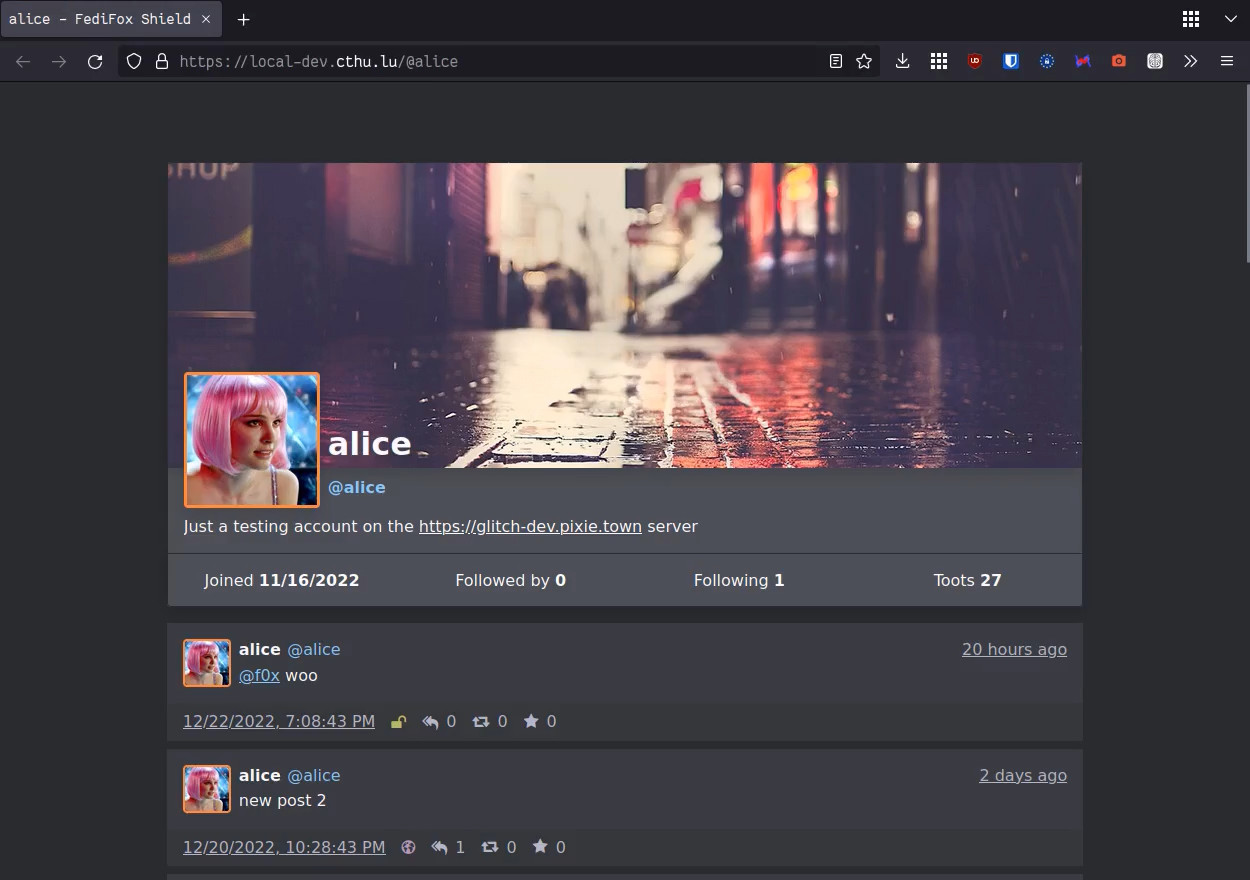
Check out the demo instance: Alice's testing thread, Bob's profile.
Motivation
FediFox Shield is my attempt to write an alternative frontend for Mastodon/Mastodon-api based instances. Mastodon (used to) provide a set of statically rendered pages for unauthenticated users. Most importantly these include publically viewable user profiles and threads.
These pages have always had some UX-papercuts, but were at least usable until disaster struck with Mastodon 4.0. Suddenly, Mastodon switched the entire frontend to be unified with the existing React based web-app for logged in users.
This means the Mastodon server only sends some basic HTML to the client, a bare skeleton for any page, and then relies on the client-side JavaScript to fetch data and render it for the user. This is fine-ish in isolation, apart from some issues (every open tab is now a fully interactive web-client, and they all play the notification sound lmao).
The glaring downside though, is that suddenly every unauthenticated user (or scraper) needs access to a lot of
API routes, to get data in a machine-readable format to render it for the user (or to scrape it and train an AI that supersedes all your shitposting capabilities).
Mastodon with the default configuration already allowed unauthenticated access to most of the same data, but
any instance administrator worth their salt has AUTHORIZED_FETCH=true enabled, which prevents this, as a
side-effect of giving your instance some more security in general.
Mastodon 4.x however, decided to completely up-end this security model without warning. AUTHORIZED_FETCH no longer prevents
any unauthenticated access to machine-readable statuses/profile data.
In it's place, a new (completely undocumented except for that pull request) config option was added: DISALLOW_UNAUTHENTICATED_API_ACCESS.
Also not ideal though, because now that the entire public-facing frontend is dependent on these routes, viewing links to profile/threads is impossible,
and you'll instead be met with a spam of 401 errors.
Enter: FediFox Shield
My initial idea was simple: provide a statically rendered alternative frontend for Mastodon, so you can still run it
with restricted API access like before, but still display some stuff publicly.
I'd started on another ActivityPub/Mastodon-api project a bit before, a web-client called FediFox, and this new project is designed to re-use
components/library logic as much as possible, so the names are similar too.
Basic architecture
React is the base of this project, it's my favorite UI paradigm by far, and as I'm already using it for FediFox (the client) I can reuse as much UI as possible. While mostly known for client-side rendering (like Mastodon uses it), it's also an incredibly powerful tool for rendering on the server side, waay more powerful than templating-based systems. React 18 released this year and made it even better with the release of 'Concurrent React' and 'Suspense' [info]. I had looked at these a bit before for delayed static rendering in Shayu but I was especially interested in using them in a dynamic webserver, to fully make use of the Streaming render functionality.
To serve an alternative static frontend, my code needs to do the following:
- get request from a user for a specific profile/thread page
- contact our actual local Mastodon instance for data on that user/thread
- render this data to static HTML
- show it to the user
There's also some routing stuff involved, because it needs to serve these on WEB_DOMAIN, as that's where externally provided links to profiles/statuses will point to. It's also where
other servers expect to federate though, so it's quite the mess of routes. For now I've settled on reverse proxying anything that starts with /@ to FediFox Shield (profiles are /@user, status/threads /@user/id).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17location / { proxy_pass http://10.0.1.1:55550; # Mastodon instance proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Server $host; } location /assets { proxy_pass http://10.0.1.2:3004; # FediFox Shield } location ~ ^/@.* { proxy_pass http://10.0.1.2:3004; # FediFox Shield }
Still leaves one edge-case though, if (remote) users want to look up your profile/status by putting the url in the search field, their instance will directly contact that URL, so FediFox Shield needs to know how to deal with that as well:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15app.use(createProxyMiddleware((_pathname, req) => { let accept = accepts(req); if (accept.type(["html", "application/activity+json", "application/ld+json"]) != "html") { log.debug("%s proxying json response from instance %s", req.url, req.get('user-agent')); return true; } else { return false; } }, { target: config.auth.instance, changeOrigin: false, // true will break http signatures! preserveHeaderKeyCase: true, xfwd: false, logLevel: 'warn' }));
It's parsing the Accept: header to distinguishing instances querying this url over a user's browser. A Browser response will prioritize html (but also adds */* so it still matches the json types),
whereas an instance query will only Accept the json types. Matched instance queries get proxied by http-proxy-middleware, with some important
options set so the HTTP signature isn't invalidated by this proxying.
Concurrent? Suspense? Streaming?
While I go into more detail in my Shayu-related post, in essence Server rendered React used to not be great with waiting on data while still rendering some other elements. You'd be forced to fully wait on whatever data you need (Mastodon API response), before you could start rendering anything, and only at the very end send that off to the client.
React 18.0 changed everything. You can now delay rendering of parts of your render tree. You wrap data-dependent components in <React.Suspense>, which defines a fallback element to show while it's still processing the
dependency for it, and when it's finished, it updates the content to your newly rendered data. In pseudo-code, the server can now do the following:
- render the basic page structure (placeholder title, overal page structure, load CSS/assets)
- encounter an element that's still waiting on data from the Mastodon API, render a placeholder loading icon
- already send what we rendered so far to the client, so you get the overal page loaded super fast
- Mastodon API finally returns our calls, and we can render the data into a profile or a thread
- Send this updated data to the client
As the response to the user's webbrowser is a single stream of HTML, you have to add a tiny bit of logic to replace the earlier sent loading element with the new content, so React adds some JavaScript to the stream for this goal. Some clients won't execute this JavaScript though (like url-previewers, or actual users who browse the web without js for weird reasons). This would result in an unusable page, since it can't display the new data properly. React SSR can accomodate this too though, as there's also an option to wait for all the Suspense to resolve, only sending the final page without any re-ordering scripts neccessary.
To signal this to the browser, a user's first request is always returned without out-of-order streaming/loading spinners, but contains a single line JS script that sets a Cookie. If the browser executes this script, that Cookie will be sent to the server on any further page loads, signalling the browser is willing to execute JavaScript, and can take full advantage of the streamed render architecture.
Streaming turned into a core part of the rendering code, dynamically loading the content out-of-order as soon as possible as it's waiting for Mastodon data on the backend (because Mastodon... is quite slow).
Internal API Structure
In my other frontend projects (like FediFox, and the GoToSocial settings interface), I've recently started using RTK Query a lot. It ties very nicely into the Redux architecture, and provides a great API for defining your API routes. Especially good is how flexible it is: a simple GET query is a very simple definition, but there's plenty of advanced use escape-hatches for more complicated (combined) queries and data transformation.
Although I'm not using Redux on the backend, I thought it would be nice to write my code in a way that still emulates a similar Query interface. Code for this is currently in server/api/query but I'll most likely split this into a separate library, because I definitely want to reuse this in future projects (and maybe you do too!).
RTK Query:
1 2 3 4 5 6 7 8 9 10 11 12 13const { createApi, fetchBaseQuery } = require("@reduxjs/toolkit/query"); const api = createApi({ baseQuery: fetchBaseQuery({ baseUrl: "/" }), endpoints: (build) => { getEmoji: build.query({ query: (id) => ({ url: `/api/v1/admin/custom_emojis/${id}` }) }), } })
FediFox Query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19const createApi = require("./query/create-api"); const fetch = require("./query/fetch"); const api = createApi({ baseQuery: fetch(config), endpoints: { account: { lookup: { query: (name) => ({ url: `/api/v1/accounts/lookup`, params: { acct: name } }), transformResponse: (data) => transformAccount(data, {sanitizeNote: true}) } } } });
It's not identical, they're slightly different usecases after all, for example RTK has a query/mutation distinction that isn't really needed here. It'll still be familiar to anyone who used RTK Query, and an accessible interface to everyone else :)
There's also possibility for more complex queries, just like with RTK Query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22const thread = { queryFn: (id, { api, ctx }) => { return Promise.all([ api.status.get(id), api.status.context(id) ]).then(([tootRes, contextRes]) => { if (tootRes.meta.isCached && contextRes.meta.isCached) { log.debug("[%s] cached thread result", ctx.id); return {meta: {isCached: true}}; } /* [...] complex parsing/transforming/re-ordering logic I'll explain later */ return { data: { maxIndent: max, thread: filtered } }; }); } },
It's reusing separately defined api routes (status.get and status.context) and due to the caching/deduplication layer it will actually re-use them when they're called separately or multiple times.
Afterwards it re-orders the returned thread, more on that later. The thread page will trigger the status.get query once in the header, to display the page's title like "alice: this is a trimmed version of my toot contents - FediFox Shield". The page's body will then trigger the status.thread query, which will re-use the same status.get response (because it's for the same status id), and load the context response, combining them after applying more transformation logic.
There's two ways the API layer keeps caches: identical requests within 5 seconds (config) of eachother will re-use the same data and instantly return it for the component.
Anything older than the immediate 5 second TTL has to be checked with the Mastodon instance for updates. A toot might've been deleted in the meantime, or a user changed their name. Mastodon provides ETag headers for API responses, so if we still had an old cache entry we can send that in our request with If-None_Match. The Mastodon instance will then verify if the result is still the same as when it replied with that ETag earlier, and if so, reply with a HTTP 304: Not Modified, without needing to send the actual data again. We can then safely re-use our cached result, updating the TTL now that we've been reassured it's still up-to-date as of now.
Biggest concern here... Mastodon can be quite slow.... Even when the response hasn't changed, it still fully processes it every time (because Mastodon does not seem to cache things at all). Only the actual sending of data is skipped on an ETag match, but that's a fraction of the response time.
No cached response:
200 api request '/api/v1/statuses/109376744610515600' took 88.579ms
200 api request '/api/v1/statuses/109376744610515600/context' took 626.920ms
finished, timings: ttfb: 4.865ms, async/api: 766.925ms, final render 6.704ms, total: 777.123ms
In-memory cached response (<5sec)
finished, timings: ttfb: 9.399ms, async/api: 121.265ms, final render 0.867ms, total: 129.941ms
ETag validation
304 api request '/api/v1/statuses/109376744610515600' took 118.258ms
304 api request '/api/v1/statuses/109376744610515600/context' took 533.434ms
finished, timings: ttfb: 9.602ms, async/api: 567.508ms, final render 0.725ms, total: 574.762ms
This setup is rendering https://glitch-dev.pixie.town/@alice/109376744610515600, a sizeable thread but nothing that long, with FediFox Shield running on the cheapest Hetzner VPS, contacting a Mastodon backend running on my homeserver connected over VDSL.
I got a trick up my sleeve for this delay though, but I'm Suspense-ing that until later.
Using API in the frontend
In old Server-rendered React you would always execute API functions like this outside the render tree, before it's even started rendering because you can only start rendering when you have an API result to render. With our Suspense flexibility though, we can execute and rely on API functions anywhere throughout our render tree. For that I wrote the UseApi component:
1 2 3 4 5 6 7 8 9 10 11 12 13<UseApi api={(api) => api.status.thread(tootId)} onError={(err) => { return ( <div className="error"> {err.error.message} </div> ); }} onData={({maxIndent, thread}) => { return <Thread thread={thread} focusId={tootId} maxIndent={maxIndent} />; }} />
source (usage) source (implementation)
Internally the structure for Suspending components is quite simple, which I mostly already figured out for Shayu.
You just have to throw a Promise inside the component if it's still pending, or use the fulfilled result/error in a normal React-Hooks component way.
If your Promise-throwing component is inside a <React.Suspense fallback={"I'm still loading"}> component you can use that to render a fallback while its children are processing.
For convenience, promises are tracked in a render/request-wide Map(), but this is not strictly neccessary.
<UseApi/> builds a little abstraction over this, providing easy access to the api functions, and working with your defined onLoading, onData and onError functions:
You can even use them to update the title of the page (calling api.status.get separately from the page contents component, while still deduplicating/re-using the result on the backend API layer.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14<head> <UseApi api={(api) => api.status.get(tootId)} onLoading={<title>FediFox Shield (loading)</title>} onError={() => <title>FediFox Shield - Error</title>} onData={(toot) => { let title = "FediFox Shield - Error"; if (toot != undefined) { title = `${toot.account.plainDisplayName}: ${toot.plainContent.slice(0, 32)} - FediFox Shield`; } return <title>{title}</title>; }} /> </head>
sidenote: the title element is weird, and you have to be careful to use a single node as it's contents. source
Combined with the API model this structure works really well, and is a breeze to set up new functionality/pages with.
Using stale data
Another neat thing I'm still experimenting with, is using 'stale' data. When we have previously fetched API data in the cache but it's older than 5 (configurable) seconds, we have to contact the Mastodon server (with an ETag header) to see if it's still valid to use. In the meantime however, we can use some nested Suspending components to send a render with our stale data to the client first (with some indicator it's still updating), and replace it with newly rendered data afterwards.
1 2 3 4 5 6<React.Suspense fallback="loading initial data"> {/* throws Promise / gets stale data result */} <React.Suspense fallback={renderComponentWithStaleData}> {/* throws Promise / uses result with fresh data */} </React.Suspense> </React.Suspense>
<UseApi> exposes this through the useStale={true} prop, and the relevant onError/onData function will get called once with stale data (if available), and then again with the fresh data.
The api prop uses a slightly different structure because internally the api status function has to be called with a second { onStaleData } argument.
1 2 3 4 5 6 7 8 9 10 11 12 13 14<UseApi api={(api) => [api.status.thread, tootId]} useStale={true} onError={(err) => { return ( <div className="error"> {err.error.message} </div> ); }} onData={({ maxIndent, thread }, { stale = false } = {}) => { return <Thread stale={stale} thread={thread} focusId={tootId} maxIndent={maxIndent} />; }} />
source (usage) source (implementation)
Project structure
Some final words about internals. I use my browserify-bundler Skulk to bundle stylesheets, and for future progressive-enhancement frontend JavaScript (media lightbox, other interactivity).
The codebase is set up to share as much as possible with FediFox (the client) through a fedifox-lib package. It holds components (Toot, Profile) with their styling css, and library functions for HTML sanitization and custom emoji replacement (and very importantly, the combination of both).
Project future
Profile and thread pages render quite well, but are still very empty. They also currently lack functionality for displaying media, and content warnings are permanently collapsed. There's also no index page or other informative instance pages like about, ToS/CoC etc.
Other areas of exploration will be ways for accounts to opt-in/opt-out to certain aspects, and better cachability (offloading static html to NGINX wherever possible).
Final words
Thanks a lot for sticking to the end of this (unexpectedly long) ramble about my latest project. I touched on all the bits I found important/interesting, but will have almost certainly missed stuff. Please feel free to reach out to me for questions/clarification, I'd be happy to reply or publish addenda. reach me on Mastodon